
Омский государственный технический университет.
Кафедра информатики и вычислительной техники.
“Система передачи дискретной информации”
ВЫПОЛНИЛ студент гр. ИВ-418
___________ Борисов К.Е.
РУКОВОДИТЕЛЬ преподаватель
___________ Белкин В.А.
ОМСК
– 2000
Содержание
Приложение А:
Текст программы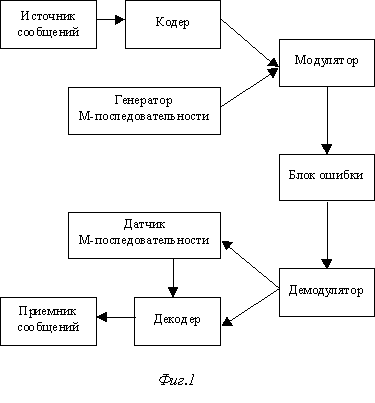
Модель системы передачи дискретной информации содержит источник сообщений, кодер, генератор М-последовательности, модулятор, блок внесения ошибки, демодулятор, датчик М-последовательности, декодер и приемник сообщений (см. фиг. 1). Источник сообщений представляет собой последовательность символов, передача которых осуществляется. Перед передачей исходная последовательность кодируется с помощью кода Хэмминга, исправляющего однократные ошибки, дополненного битом проверки на четность. Перед сообщением в канале связи находится М-последовательность, которая выполняет функции синхронизации приемника и передатчика, позволяя определить начало сообщения. Модулятор заменяет каждый бит, передаваемый в канал, группой таких битов заданной заранее длины. Все полученные биты искажаются ошибкой. Демодулятор принимает группы искаженных бит и заменяет их одним битом, значение которого определяется по методу большинства. Датчик М-последовательности определяет начало приема сообщения. Декодер производит обнаружение и исправление внесенных в сообщение ошибок. Приемник сообщений представляет собой буфер, в котором хранится принятое сообщение.
2.
Алгоритм функционирования системыКанал
связи представляет собой массив байтов, в который последовательно заносятся белый шум, М-последовательность и кодированные сообщения. М-последовательность получается из шестибитового начального блока рекуррентной процедурой с использованием специальных таблиц, содержащих коэффициенты порождающих многочленов. Очередной бит последовательности определяется следующим образом:![]() где d – биты последовательности, a – табличные коэффициенты.
где d – биты последовательности, a – табличные коэффициенты.
Коэффициенты подобраны так, чтобы полученная последовательность содержала все возможные шестибитовые комбинации
, кроме нулевой.Кодированные сообщения представляют собой байты, 4 бита каждого из которых содержат биты передаваемого сообщения, 3 бита содержат контрольные биты, позволяющие исправлять однократные ошибки,
1 бит реализует контроль четности, позволяя отличать двукратные ошибки от однократных.![]() Перед помещением в канал связи все биты заменяются группами бит. Длина таких групп нечетна и задается заранее. Каждый полученный таким образом бит может быть искажен ошибкой с заданной заранее вероятностью. Реализуется два метода внесения ошибки. Первый метод предполагает последовательный перебор всех битов канала связи, для каждого бита реализуется случайная величина, значение которой определяет, будет ли инвертирован текущий бит. По второму методу считается число бит, которое надо исказить как
Перед помещением в канал связи все биты заменяются группами бит. Длина таких групп нечетна и задается заранее. Каждый полученный таким образом бит может быть искажен ошибкой с заданной заранее вероятностью. Реализуется два метода внесения ошибки. Первый метод предполагает последовательный перебор всех битов канала связи, для каждого бита реализуется случайная величина, значение которой определяет, будет ли инвертирован текущий бит. По второму методу считается число бит, которое надо исказить как
![]() где N – число искажаемых бит, Perr – вероятность искажения бита, L – длина содержимого канала связи. Затем в канале связи инвертируется N различных бит, позиция которых определяются с помощью генератора последовательности псевдослучайных чисел. Последовательность псевдослучайных чисел задается следующей рекуррентной формулой:
где N – число искажаемых бит, Perr – вероятность искажения бита, L – длина содержимого канала связи. Затем в канале связи инвертируется N различных бит, позиция которых определяются с помощью генератора последовательности псевдослучайных чисел. Последовательность псевдослучайных чисел задается следующей рекуррентной формулой:
где
X – значения последовательности, а A, B и C – параметры.Параметры выбираются с тем расчетом, чтобы длина последовательности была равна
C, то есть чтобы перебирались все значения на отрезке [0, C-1].Затем выделенные в канале группы битов заменяются одним битом,
значение которого определяется значением большинства битов в группе. Таким образом, чем больше длина группы битов, тем меньше вероятность искажения бита сообщения при заданной вероятности искажения бита в канале.После того, как таким образом сформировано содержимое канала, начинается поиск М-последовательности. Поиск производится путем последовательных сдвигов содержимого канала на один бит с тестированием на совпадение первых битов канала с первыми битами М-последовательности
. Заранее задается число совпадающих бит, достаточное для обнаружения М-последовательности. При обнаружении М-последовательности следующие биты интерпретируются как биты сообщения и декодируются с исправлением однократных ошибок.
3.
Результаты исследования системы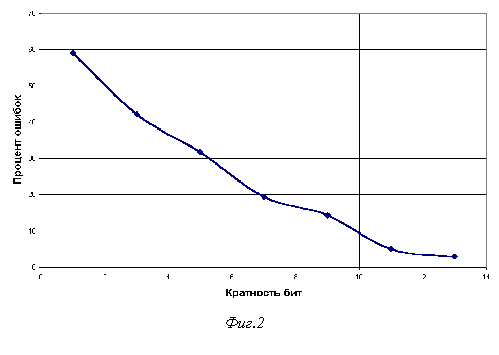
На графике (см. фиг
. 2) показана зависимость процента искаженных сообщений в канале, то есть сообщений, имеющих ненулевой вектор ошибки при декодировании или неверный бит четности.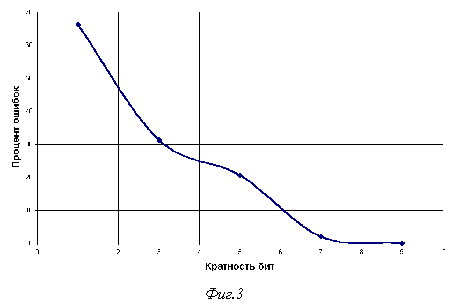
Процент реального искажения символов, то есть процент различных символов в переданном и полученном сообщений убывает быстрее
(см. фиг.3).Увеличение кратности размножения бит в канале соответствует снижению скорости передачи в такое же число раз, поэтому на практике с ошибками обычно борются, улучшая характеристики канала связи, то есть уменьшая вероятность искажения бита.
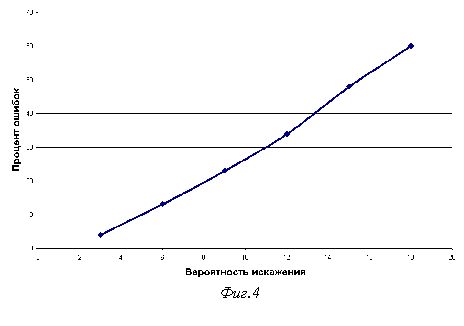
Зависимость между процентом неверно переданных символов и вероятностью искажения одного бита показана на фиг.4. Можно эффективно уменьшать число ошибок, так как зависимость практически линейна. На практике на снижение скорости передачи идут только в тех случаях, когда нельзя повысить качество канала до приемлемого уровня.
Приложение А. Текст программы.
#include <stdio.h>
#include <conio.h>
#include <process.h>
#include <stdlib.h>
#include <string.h>
// Error codes
#define erHem 1 // Сообщение слишком большой длины (более 4 бит)
#define erPow 2 // Неверный вектор ошибки
#define erMem 3 // Нет памяти
#define erPEr 4 // Неверное значение вероятности ошибки
// Colors
#define clrRight 15 // Цвет правильно переданного сообщения
#define clrFixed 9 // Цвет исправленного сообщения
#define clrBad 12 // Цвет неисправимого сообщения
#define clrInfo 10 // Цвет информационных надписей
#define clrComm 7 // Цвет обычного цвета
// M-sequence
// #define poly 0x30 // Веса 21, 2d, 30 для генерации М-последовательности
// Interface
#define mskCrt 0x80 // Mask for critical error
#define mskFix 0x40 // Mask for fixed message
// Config
#define MultLev 1l // Кратность битов
#define mOutStrt 3 // Начальное значение для М-последовательности передатчика
#define mInStrt 3 // Начальное значение для М-последовательности приемника
#define mOutPoly 0x30 // Веса для М-последовательности передатчика
#define mInPoly 0x30 // Веса для М-последовательности приемника
#define mLev 50 // Уровень совпадения М-последовательностей
#define MaxNoiseLen 20 // Длина шума в байтах
// Glucker
#define glkMode 1 // Тип ошибки: 0 - число ошибок распределено нормально
// 1 - число ошибок фиксированно (PErr*Len)
// X(i+1)=(AX+B) mod MAX
// MAX: A, B
// 200: 61, 1
// 1000: 61, 1; 41, 1; 21, 1
#define glkMax 1000 // Длина периода псевдослучайной последовательности
#define glkA 61 // Параметры генератора псевдослучайной последовательности
#define glkB 1
// Variables
unsigned char *chan; // Содержимое канала связи
unsigned char *mchan; // Содержимое канала связи с размноженными битами
unsigned int chanlen; // Длина содержимого канала
unsigned char mseq[8]; // М-последовательность
unsigned char *messbuf; // Буффер сообщения
unsigned char *reicbuf; // Полученное сообщение
unsigned char *realbuf; // Отправленное сообщение
unsigned int messlen; // Длина сообщения
double PErr; // Вероятность ошибки в бите
unsigned char poly=0x30; // Веса 21, 2d, 30 для генерации М-последовательности
unsigned char mStrt=5; // Начальный блок М-последовательности
unsigned int NoiseLen=0; // Длина шума
unsigned int BadBits; // Число исскаженых бит
// Functions
void Error(unsigned char cod); // Произошла ошибка
unsigned char HemnPar(unsigned char x); // Контрольные разряды и бит четности
unsigned char UnHemnPar(unsigned char x); // Исправление ошибок и декодирование
unsigned char UnCod(unsigned char x); // Выборка информационных бит
unsigned char Cod(unsigned char x, unsigned char ctrl); // Внос контрольной информации
unsigned char ErMsk(unsigned char x); // Степень двойки для исправления ошибки
void PrintSeq(void); // Распечатка М-последовательности
void GenerateSeq(unsigned char *seq); // Генерация М-последовательности, начиная со значения mStrt
void PagerOut(unsigned char *str); // Посылка сообщения
void PagerIn(void); // Прием сообщения
void AddMess(void); // Добавление сгенерированного сообщения
void AddSeq(void); // Добавление M-последовательности
void AddNoise(unsigned int len); // Добавление len байт шума
char CheckMSeq(void); // Проверка на начало сообщения
void TimeClk(void); // Сдвиг содержимого канала на 1 бит
void MultiBit(void); // Размножение битов в канале связи
void UnMultiBit(void); // Интергрирование битов
void FreeAll(void); // Освобождение всей памяти
void PrintConf(void); // Печать настроек
void Error(unsigned char cod) // Произошла ошибка
{
switch(cod)
{
case erHem: printf("Невозможно построить код Хемминга, т.к. сообщение слишком длинное (>4бит).");break;
case erPow: printf("Неверный вектор ошибки.");break;
case erMem: printf("Мало памяти.");break;
case erPEr: printf("Неверное значение вероятности ошибки.");break;
default: printf("Неизвестная ошибка.");
}
printf("/r/n");
FreeAll();
exit(cod);
}
void FreeAll(void) // Освобождение всей памяти
{
free(messbuf);
free(chan);
free(mchan);
}
void PrintConf(void) // Печать настроек
{
textcolor(clrInfo);
cprintf("/r/nТЕКУЩИЕ НАСТРОЙКИ:");
textcolor(clrComm);
cprintf("/r/nВероятность искажения одного бита: %5.2f%", PErr*100);
cprintf("/r/nКратность размножения бита: %i", MultLev);
cprintf("/r/nПорог распознавания М-последовательности:
%i", mLev);cprintf("/r/nДлина шума: %i(бит)", NoiseLen*8);
}
void MultiBit(void) // Размножение битов в канале связи
{
unsigned long int i;
unsigned char bit; // Текущий бит
unsigned char msk[8]={1, 2, 4, 8, 16, 32, 64, 128}; // Маски для выделения битов
mchan=(unsigned char *)realloc(mchan, (unsigned int)(MultLev*chanlen)); // Длина в MultLev раз больше
for(i=0; i<MultLev*chanlen; i++) mchan[(unsigned int)i]=0; // Обнуляем
for(i=0; i<MultLev*8*chanlen; i++) // Перебираем все биты результата
{
bit=chan[(unsigned int)((i/MultLev)/8)]; // Считываем байт
bit&=msk[(unsigned int)((i/MultLev)%8)]; // Выделяем бит
if(bit) mchan[(unsigned int)(i/8)]|=msk[(unsigned int)(i%8)]; // Записываем бит в результат
}
}
void UnMultiBit(void) // Интергрирование битов
{
unsigned long int i, j;
unsigned char bit; // Текущий бит
unsigned int n; // Число единичек в блоке
unsigned char msk[8]={1, 2, 4, 8, 16, 32, 64, 128}; // Маски для выделения битов
for(i=0; i<chanlen; i++) chan[(unsigned int)i]=0; // Обнуляем
for(i=0; i<MultLev*8*chanlen;) // Перебираем все биты результата
{
n=0;
for(j=0; j<MultLev; j++) // Все биты в блоке
{
bit=mchan[(unsigned int)(i/8)]; // Считываем байт
bit&=msk[(unsigned int)(i%8)]; // Выделяем бит
if(bit) n++;
i++; // Следующий бит в канале
}
if(n>MultLev/2) chan[(unsigned int)(((i/MultLev)-1)/8)]|=msk[(unsigned int)(((i/MultLev)-1)%8)]; // Записываем бит в результат
}
}
void TimeClk(void) // Сдвиг содержимого канала на 1 бит
{
unsigned int i;
unsigned char bit;
for(i=0; i<chanlen; i++) // Перебираем все символы
{
bit=chan[i+1]&0x80; // Старший бит следующего байта
chan[i]<<=1; // Сдвиг текущего бита
chan[i]|=bit?1:0; // Перенос старшего бита из следующего байта
}
}
char CheckMSeq(void) // Проверка на начало сообщения
{
unsigned int i, j;
unsigned char rollbit; // "Бегущая единичка"
unsigned char res; // Число совпадений битов
res=0;
for(i=0; i<8; i++) // Цикл по байтам
{
rollbit=1;
for(j=0; j<8; j++) // Цикл по битам
{
if(!((chan[i]^mseq[i])&rollbit)) // Биты совпадают
{
res++;
}
rollbit<<=1; // Следующий бит
}
}
return(res>=mLev?1:0);
}
void GenerateSeq(unsigned char *seq) // Генерация М-последовательности, начиная со значения a
{
int i, j;
unsigned char nxt; // Следующий разряд
unsigned char tmp;
for(i=0; i<8; i++) seq[i]=0;
seq[0]=mStrt;
for(i=0; i<64; i++)
{
tmp=seq[0]&poly;
nxt=0;
for(j=0; j<6; j++) // Суммирование выделенных разрядов по модулю 2
{
nxt^=tmp;
tmp>>=1;
}
nxt&=1; // Последний разряд
// Сдвиг
seq[7]<<=1;
for(j=6; j>=0; j--)
{
tmp=seq[j]&128; // Старший разряд переносится в следующий байт
if(tmp) seq[j+1]|=1;
seq[j]<<=1;
}
// Добавим новый разряд
if(nxt) seq[0]|=1;
// cprintf(nxt?"1":"0"); // Печать бита
/* // Печатаем очередное получившееся число
printf("%i ", mseq[0]&0x3f); // Шесть младших бит*/
}
}
void PrintSeq(void) // Распечатка М-последовательности
{
unsigned char i, j;
unsigned char tmp;
textcolor(clrComm);
for(i=0; i<8; i++) // Цикл по байтам
{
tmp=1;
for(j=0; j<8; j++) // Цикл по битам
{
cprintf("%d", (mseq[i]&tmp)?1:0); // Вывод бита
tmp<<=1; // Следующий бит
}
}
}
unsigned char HemnPar(unsigned char x) // Контрольные разряды и бит четности
{
// P1=P3+P5+P7 // Контрольные разряды, P8 - бит четности
// P2=P3+P6+P7
// P4=P5+P6+P7
const unsigned char tbl[16]= // Таблица значений
{0, 14, 7, 9, 11, 5, 12, 2, 13, 3, 10, 4, 6, 8, 1, 15};
// Формат таблицы следующий: P1.P2.P4.P8
if(x&0xf0) // Можно обрабатывать лишь сообщения длиной 4бита.
{
Error(erHem);
}
else
{
return(Cod(x, tbl[x])); // Вносим контрольную информацию
}
return(0); // От дураков
}
unsigned char UnHemnPar(unsigned char x) // Исправление ошибок и декодирование
{
// C3=P1+P3+P5+P7
// C2=P2+P3+P6+P7
// C1=P4+P5+P6+P7
// (C1, C2, C3) - Вектор ошибки (номер разряда в двоичном представлении)
const unsigned char mask[3]={0x1e, 0x66, 0xaa}; // Маски разрядов для C1, C2, C3 соответственно
unsigned char erpos; // Позиция ошибки
unsigned char parity; // Четность
unsigned char mskx; // Отмаскированное сообщение
unsigned char tmp;
int i, j;
erpos=0;
for(i=0; i<3; i++) // Находим номер ошибки
{
mskx=x&mask[i]; // Наложим маску
tmp=0;
for(j=0; j<7; j++) // Анализируем все биты, кроме бита четности
{
if(mskx&0x80) // Единичный бит
{
tmp=tmp?0:1;
}
mskx<<=1; // Анализ следующего бита
}
erpos|=tmp; // Запоминаем C(i)
erpos<<=1; //C(i+1)
}
erpos>>=1;
mskx=x;
parity=0; // Четно
for(j=0; j<8; j++) // Анализируем все биты
{
if(mskx&0x80)
{
parity=parity?0:1; // Меняем четность
}
mskx<<=1;
}
if(erpos) // Ошибка
{
if(parity) // Однократная, можно исправить
{
tmp=x^ErMsk(erpos); // Исправляем
return(UnCod(tmp)|mskFix); // Спец. значение в старшей части
}
else // Исправить нельзя
{
return(UnCod(x)|mskCrt); // Спец. значение в старшей части
}
}
else // Ошибки либо нет, либо в бите четности
{
return(UnCod(x));
}
}
unsigned char Cod(unsigned char x, unsigned char ctrl) // Внос контрольной информации
{
// x - исходное сообщение
// ctrl - контрольные биты и бит четности
unsigned char res;
unsigned char tmp;
res=x;
res<<=1; // Освободим место под бит четности
res&=0x0f; // Освободимся от вдвинувшегося бита
res|=(ctrl&1); // Внесем бит четности
tmp=ctrl&0x0c; // C1.C2
tmp|=(ctrl>>1)&1; // C3
tmp|=(x&8)>>2; // P3
tmp<<=4; // tmp - это старшая часть
res|=tmp; // Сольем
return(res);
}
unsigned char UnCod(unsigned char x) // Выборка информационных бит
{
unsigned char res;
unsigned char tmp;
res=tmp=x;
res&=0x0e; // Избавимся от бита четности
res>>=1; // Подровняем
tmp&=0x20; // Избавимся от контрольных битов
tmp>>=2; // Подровняем
res|=tmp; // Сольем в одно
return(res);
}
unsigned char ErMsk(unsigned char x) // Степень двойки для исправления ошибки
{
const unsigned char tbl[7]= // Таблица возвращаемых масок
{0x80, 0x40, 0x20, 0x10, 0x08, 0x04, 0x02};
if((x==0) || (x>7)) Error(erPow); // Неверный вектор
else return(tbl[x-1]);
return(0); // От дураков
}
void Glucker(void) // Внесение ошибки в бит
{
unsigned int i;
unsigned char bit;
BadBits=0;
if(!glkMode)
{
// Нормальное распределение числа ошибок
unsigned int intPErr=PErr*RAND_MAX;
unsigned int j;
if(PErr>1 || PErr<0) Error(erPEr);
for(i=0; i<MultLev*chanlen; i++) // Перебираем все символы
{
bit=0x01;
for(j=0; j<8; j++) // Перебираем все биты
{
if(rand()<intPErr)
{
mchan[i]^=bit;
BadBits++; // Счетчик испорченных битов
}
bit<<=1;
}
}
}
else
{
// Фиксированное распределение числа ошибок
unsigned int x; // Текущее значение случайной величины
unsigned long int pos; // Текущая позиция
unsigned long int maxpos; // Максимальная позиция
unsigned int ErrNum; // Число ошибок в блоке
float RealErrNum; // Вещественное значение числа ошибок, нуждается в округлении
unsigned char bits[8]={1, 2, 4, 8, 16, 32, 64, 128}; // Биты
x=random(glkMax); // Начальное значение случайной величины
pos=0; // Искажая шум, мы ничего не портим
maxpos=MultLev*8*chanlen; // Тоже верно
// pos=MultLev*NoiseLen; // Пропустим шум
// maxpos=MultLev*8*(NoiseLen+8+2*messlen); // Максимальное число бит
while(pos<maxpos) // Начиная с М-последовательности, до конца сообщения
{
RealErrNum=PErr*((maxpos-pos)>glkMax?glkMax:(maxpos-pos));
ErrNum=(unsigned int)(2*RealErrNum-(int)(RealErrNum)); // Реализуется round
for(i=0; i<ErrNum;) // Определим число ошибок на заданном интервале
{
if((x+pos)<maxpos) // Ошибка в нужном интервале
{
mchan[(unsigned int)((x+pos)/8)]^=bits[(unsigned int)(x+pos)%8]; // Вносим ошибку
BadBits++; // Счетчик испорченных битов
i++; // Увеличиваем счетчик ошибок
}
x=(glkA*x+glkB)%glkMax; // Следующее значение последовательности
}
pos+=glkMax; // Переходим к следующему блоку
}
}
}
void AddNoise(unsigned int len) // Добавить len байт шума
{
int i;
chanlen+=len; // Увеличиваем длину
chan=(unsigned char *)realloc(chan, chanlen); // Выделяем дополнительную память
for(i=chanlen; i>=(int)chanlen-(int)len; i--) // Добавляем мусор
{
chan[i]=random(256);
}
}
void AddMess(void) // Добавить сгенерированное сообщение
{
int i;
unsigned int oldlen;
oldlen=chanlen;
chanlen+=2*messlen; // Увеличиваем длину
chan=(unsigned char *)realloc(chan, chanlen); // Выделяем дополнительную память
for(i=chanlen-1; i>=(int)chanlen-(int)2*(int)messlen; i--) // Добавляем мусор
{
chan[i]=messbuf[i-oldlen];
}
}
void AddSeq(void) // Добавить М-последовательнось
{
int i;
unsigned int oldlen;
oldlen=chanlen;
chanlen+=8; // Увеличиваем длину
chan=(unsigned char *)realloc(chan, chanlen); // Выделяем дополнительную память
for(i=chanlen-1; i>=(int)chanlen-(int)8; i--) // Добавляем мусор
{
chan[i]=mseq[i-oldlen];
}
}
void PagerOut(unsigned char *str) // Посылка сообщения
{
unsigned int i;
unsigned char tmp;
unsigned int len=strlen(str);
if(messbuf) free(messbuf); // Если было сообщение, то уберем его
messbuf=(unsigned char *)malloc(2*len);
if(!messbuf)
{
Error(erMem);
}
messlen=len;
textcolor(clrInfo);
cprintf("/r/n/r/nПОСЛАНО СООБЩЕНИЕ: ");
textcolor(clrComm);
cprintf("%s", str);
for(i=0; i<len; i++)
{
tmp=str[i];
messbuf[2*i]=HemnPar(tmp&0x0f); // Младшая часть
messbuf[2*i+1]=HemnPar(tmp>>4); // Старшая часть
}
printf("/r/n");
}
void PagerIn(void) // Прием сообщения
{
unsigned int i, j;
unsigned char tmp;
unsigned char res; // Декодированное сообщение
unsigned int NumBad; // Число неверных символов
unsigned int WrappedBits; // Число неверных бит
int col; // Цвет
reicbuf=(unsigned char *)malloc(messlen); // Полученное сообщение
textcolor(clrInfo);
cprintf("ПРИНЯТО СООБЩЕНИЕ: ");
textcolor(clrComm);
NumBad=0;
WrappedBits=0;
for(i=4; i<messlen+4; i++) // Считываем messlen символов (длина сообщения оговаривается заранее)
{
col=clrRight;
tmp=UnHemnPar(chan[2*i]);
for(j=1; j<=128; j<<=1) // Подсчет числа искаженных бит
{
if((chan[2*i]^messbuf[2*i-8])&j) WrappedBits++;
if((chan[2*i+1]^messbuf[2*i-7])&j) WrappedBits++;
}
if(tmp&mskCrt) // Сообщение с ошибкой
{
col=clrBad;
tmp&=0x0f;
NumBad++;
}
if(tmp&mskFix) // Сообщение с исправленной ошибкой
{
col=clrFixed;
tmp&=0x0f;
NumBad++;
}
res=UnHemnPar(chan[2*i+1]);
if(res&mskCrt) // Сообщение с ошибкой
{
col=clrBad;
res&=0x0f;
NumBad++;
}
if((res&mskFix) && (col==clrRight)) // Сообщение с исправленной ошибкой
{
col=clrFixed;
tmp&=0x0f;
NumBad++;
}
res<<=4;
res|=tmp; // Сливаем два сообщения в одно
textcolor(col);
cprintf("%c", res);
reicbuf[i-4]=res; // Запомним принятое
}
printf("/r/n");
textcolor(clrInfo);
cprintf("/r/nОбнаружено искаженных сообщений: ");
textcolor(clrComm);
cprintf("%i сообщений (%6.2f/%)", NumBad, (NumBad*100.0)/(2*messlen));
// Оценка правильности передачи
NumBad=0;
for(i=0; i<messlen; i++)
{
if(reicbuf[i]!=realbuf[i]) NumBad++; // Неверный символ
}
textcolor(clrInfo);
cprintf("/r/nНеверно передано: ");
textcolor(clrComm);
cprintf("%i байт (%6.2f/%)", NumBad, (NumBad*100.0)/messlen);
textcolor(clrInfo);
cprintf("/r/nИскажено 'размноженных' бит: ");
textcolor(clrComm);
cprintf("%i бит (%6.2f/%)", BadBits, (BadBits*100.0)/(chanlen*8.0*MultL
ev));// cprintf("%i бит (%6.2f/%)", BadBits, (BadBits*100.0)/(MultLev*8*(8+2*messlen)));
textcolor(clrInfo);
cprintf("/r/nИскажено реальных бит: ");
textcolor(clrComm);
cprintf("%i бит (%6.2f/%)", WrappedBits, (WrappedBits*100.0)/(messlen*2*8.0));
free(reicbuf);
}
void main(void)
{
unsigned int i;
// Инициализация
messbuf=NULL;
messlen=0;
chan=NULL;
mchan=NULL;
chanlen=0;
PErr=0.03;
randomize();
NoiseLen=random(MaxNoiseLen);
clrscr();
PrintConf();
while(kbhit()) getch();
mStrt=mOutStrt;
poly=mOutPoly;
GenerateSeq(mseq); // М-последовательность для передатчика
realbuf="/r/nПередаем достаточно длинное сообщение, пытаясь исправить вносящиеся ошибки. Белым цветом обозначены символы, при передаче которых ошибки не обнаружены. Синим цветом показаны исправленные символы. Красным цветом показаны символы, в которых обнаружены неисправимые ошибки.";
PagerOut(realbuf); // Переданное сообщение
AddNoise(NoiseLen);
AddSeq(); // М-последовательность
AddMess(); // Сообщение
MultiBit(); // Размножаем биты
Glucker(); // Ошибка
UnMultiBit(); // Сливаем биты
mStrt=mInStrt;
poly=mInPoly;
GenerateSeq(mseq); // М-последовательность для приемника
i=0;
while((!CheckMSeq())&&(i<(chanlen*8)))
{
TimeClk();
i++;
}
if(i!=(chanlen*8))
{
textcolor(clrFixed);
cprintf("/r/nСообщение обнаружено на позиции %i.", i);
}
else
{
textcolor(clrBad);
cprintf("/r/nСообщение не обнаружено.");
}
printf("/r/n/r/n");
PagerIn(); // Принятое сообщение
textcolor(7);
while(kbhit()) getch();
getch();
FreeAll();
}