Государственный комитет Российской Федерации по высшей школе
Омский государственный технический университет
Кафедра информатики и вычислительной техники
Построение параллельных компьютеров.
Государственный комитет Российской Федерации по высшей школе
Омский государственный технический университет
Кафедра информатики и вычислительной техники
Построение параллельных компьютеров.
Выполнил студент гр.ИВ-618
| Борисов К.Е. |
Руководитель работы
| Нестерук В.Ф. |
|
|
|
|
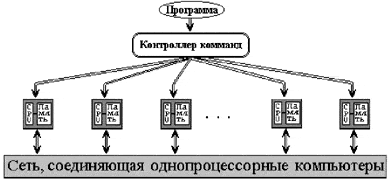
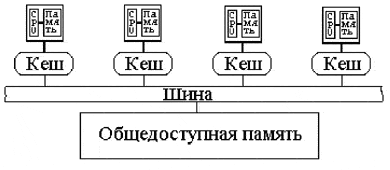
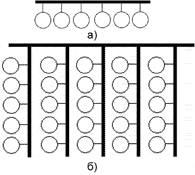
В некоторых архитектурах каждый процессор имеет как прямой доступ к общей памяти, так и собственную локальную память(рис. ).
|
Системы с виртуальной разделяемой памятью имеют ту же схему, что и системы с распределенной памятью (рис. 3). Их отличие состоит в том, что в системах с виртуальной разделяемой памятью процессоры при необходимости взаимодействия не обмениваются сообщениями, а генерируют обращение к памяти другого процессора, как к своей. Обращение к „чужой“ памяти идет на порядок (или даже более) медленнее.
В таких системах отдельную проблему представляет согласование кэшей всех процессоров. Этот вопрос будет рассмотрен ниже.
Соответственно, описание любого вычислительного элемента включает набор из трех пар целых чисел:
|
При классификации используются следующие символы:
Например, процессор CDC 6600 имеет ЦПУ с десятью процессорами ввода/вывода. Один управляющий блок контроллирует одно АЛУ с длиной слова 60 бит. АЛУ имеет 10 функциональных блоков, которые могут быть организованны в конвейер. 10 процессоров ввода/вывода могут работать параллельно друг с другом и с ЦПУ. Каждый процессор ввода/вывода содержит 12-ти битное АЛУ. Структура такой вычислительной системы описывается следующим образом:
|
|
|
Процессор Cray-1 - это 64-х битный процессор, его АЛУ имеет 12 функциональных блоков, восемь из которых могут быть связаны в конвейер, различные функциональные устройства имеют от 1 до 14 сегментов, которые также могут работать в конвейере. Описатель в этом случае будет иметь следующий вид:
|
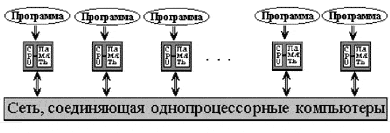
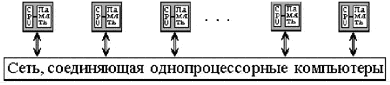
По структуре оперативной памяти существующие вычислительные системы делятся на две большие группы: либо это системы с общей памятью, прямо адресуемой всеми процессорами, либо это системы с распределенной памятью, каждая часть которой доступна только одному процессору. Одновременно с этим, и для межпроцессорного взаимодействия существуют две альтернативы: через разделяемые переменные или с помощью механизма передачи сообщений. Исходя из таких предположений, можно получить четыре класса MIMD архитектур, уточняющих систематику Флинна:
Опираясь на такое деление, Джонсон вводит названия для некоторых классов. Так вычислительные системы, использующие общую разделяемую память для межпроцессорного взаимодействия и синхронизации, он называет системами с разделяемой памятью, например, CRAY Y-MP (по его классификации это класс 1). Системы, в которых память распределена по процессорам, а для взаимодействия и синхронизации используется механизм передачи сообщений он называет архитектурами с передачей сообщений, например NCube, (класс 3). Системы с распределенной памятью и синхронизацией через разделяемые переменные, как в BBN Butterfly, называются гибридными архитектурами (класс 2).
В качестве уточнения классификации автор отмечает возможность учитывать различные виды связи между процессорами: общая шина, переключатели, разнообразные сети и т.п.
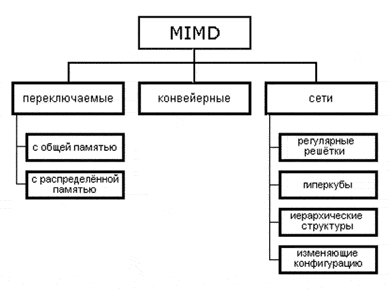
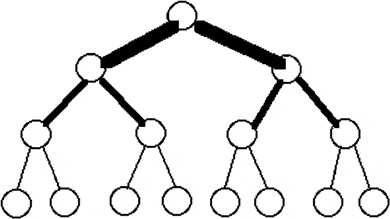
Как отмечалось выше (см. классификацию Флинна), класс MIMD чрезвычайно широк, причем наряду с большим числом компьютеров он объединяет и целое множество различных типов архитектур. Хокни, пытаясь систематизировать архитектуры внутри этого класса, получил иерархическую структуру, представленную на рис. .
|
Основная идея классификации состоит в следующем. Множественный поток команд может быть обработан двумя способами: либо одним конвейерным устройством обработки, работающем в режиме разделения времени для отдельных потоков, либо каждый поток обрабатывается своим собственным устройством. Первая возможность используется в MIMD компьютерах, которые автор называет конвейерными (например, процессорные модули в Denelcor HEP). Архитектуры, использующие вторую возможность, в свою очередь опять делятся на два класса:
Далее, среди MIMD машин с переключателем Хокни выделяет те, в которых вся память распределена среди процессоров как их локальная память (например, PASM, PRINGLE). В этом случае общение самих процессоров реализуется с помощью очень сложного переключателя, составляющего значительную часть компьютера. Такие машины носят название MIMD машин с распределенной памятью. Если память это разделяемый ресурс, доступный всем процессорам через переключатель, то такие MIMD являются системами с общей памятью (CRAY X-MP, BBN Butterfly). В соответствии с типом переключателей можно проводить классификацию и далее: простой переключатель, многокаскадный переключатель, общая шина.
Многие современные вычислительные системы имеют как общую разделяемую память, так и распределенную локальную. Такие системы автор рассматривает как гибридные MIMD c переключателем.
При рассмотрении MIMD машин с сетевой структурой считается, что все они имеют распределенную память, а дальнейшая классификация проводится в соответствии с топологией сети: звездообразная сеть (lCAP), регулярные решетки разной размерности (Intel Paragon, CRAY T3D), гиперкубы (NCube, Intel iPCS), сети с иерархической структурой, такой, как деревья, пирамиды, кластеры (Cm*, CEDAR) и, наконец, сети, изменяющие свою конфигурацию.
Заметим, что если архитектура компьютера спроектирована с использованием нескольких сетей с различной топологией, то, по всей видимости, по аналогии с гибридными MIMD с переключателями, их стоит назвать гибридными сетевыми MIMD, а использующие идеи разных классов - просто гибридными MIMD. Типичным представителем последней группы, в частности, является компьютер Connection Machine 2, имеющим на внешнем уровне топологию гиперкуба, каждый узел которого является кластером процессоров с полной связью.
Классификация Дж.Шора, появившаяся в начале 1973 году, интересна тем, что представляет собой попытку выделения типичных способов компоновки вычислительных систем на основе фиксированного числа базисных блоков: устройства управления, арифметико-логического устройства, памяти команд и памяти данных. Дополнительно предполагается, что выборка из памяти данных может осуществляться словами, то есть выбираются все разряды одного слова, и/или битовым слоем - по одному разряду из одной и той же позиции каждого слова (иногда эти два способа называют горизонтальной и вертикальной выборками соответственно). Конечно же, при анализе данной классификации надо делать скидку на время ее появления, так как предусмотреть невероятное разнообразие параллельных систем настоящего времени было в принципе невозможно. Итак, согласно классификации Шора все компьютеры разбиваются на шесть классов, которые он так и называет: машина типа I, II и т.д.
|
Машина I - это вычислительная система, которая содержит устройство управления, арифметико-логическое устройство, память команд и память данных с пословной выборкой. Считывание данных осуществляется выборкой всех разрядов некоторого слова для их параллельной обработки в арифметико-логическом устройстве. Состав АЛУ специально не оговаривается, что допускает наличие нескольких функциональных устройств, быть может конвейерного типа. По этим соображениям в данный класс попадают как классические последовательные машины (IBM 701, PDP-11, VAX 11/780), так и конвейерные скалярные (CDC 7600) и векторно-конвейерные (CRAY-1).
|
Если в машине I осуществлять выборку не по словам, а выборкой содержимого одного разряда из всех слов, то получим машину II. Слова в памяти данных по прежнему располагаются горизонтально, но доступ к ним осуществляется иначе. Если в машине I происходит последовательная обработка слов при параллельной обработке разрядов, то в машине II - последовательная обработка битовых слоев при параллельной обработке множества слов.
Структура машины II лежит в основе ассоциативных компьютеров (например, центральный процессор машины STARAN), причем фактически такие компьютеры имеют не одно арифметико-логическое устройство, а множество сравнительно простых устройств поразрядной обработки. Другим примером служит матричная система ICL DAP, которая может одновременно обрабатывать по одному разряду из 4096 слов.
|
Если объединить принципы построения машин I и II, то получим машину III. Эта машина имеет два арифметико-логических устройства - горизонтальное и вертикальное, и модифицированную память данных, которая обеспечивает доступ как к словам, так и к битовым слоям. Впервые идею построения таких систем в 1960 году выдвинул У.Шуман , называвший их ортогональными (если память представлять как матрицу слов, то доступ к данным осуществляется в направлении, „ортогональном“ традиционному - не по словам (строкам), а по битовым слоям (столбцам)). В принципе, как машину STARAN, так и ICL DAP можно запрограммировать на выполнение функций машины III, но поскольку они не имеют отдельных АЛУ для обработки слов и битовых слоев, отнести их к данному классу нельзя. Полноправными представителями машин класса III являются вычислительные системы семейства OMEN-60 фирмы Sanders Associates, построенные в прямом соответствии с концепцией ортогональной машины.
|
Если в машине I увеличить число пар „арифметико-логическое устройство - память данных“ (иногда эту пару называют процессорным элементом) то получим машину IV. Единственное устройство управления выдает команду за командой сразу всем процессорным элементам. С одной стороны, отсутствие соединений между процессорными элементами делает дальнейшее наращивание их числа относительно простым, но с другой, сильно ограничивает применимость машин этого класса. Такую структуру имеет вычислительная система PEPE, объединяющая 288 процессорных элементов.
|
Если ввести непосредственные линейные связи между соседними процессорными элементами машины IV, например в виде матричной конфигурации, то получим схему машины V. Любой процессорный элемент теперь может обращаться к данным как в своей памяти, так и в памяти непосредственных соседей. Подобная структура характерна, например, для классического матричного компьютера ILLIAC IV
|
Заметим, что все машины с I-ой по V-ю придерживаются концепции разделения памяти данных и арифметико-логических устройств, предполагая наличие шины данных или какого-либо коммутирующего элемента между ними. Машина VI, названная матрицей с функциональной памятью (или памятью с встроенной логикой), представляет собой другой подход, предусматривающий распределение логики процессора по всему запоминающему устройству. Примерами могут служить как простые ассоциативные запоминающие устройства, так и сложные ассоциативные процессоры.
|
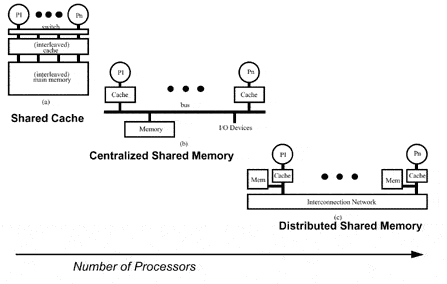
На рис. 13 показаны различные способы организации разделяемой памяти с упорядочением по возможному числу параллельно работающих процессоров.
Кроме того, для таких систем появляется проблема когерретности кэшей. Она заключается в том, что одна и та же ячейка памяти может содержаться в нескольких кэшах одновременно. Тогда ее модификация в одном из кэшей приводит к несогласованности кэшей - остальные кэши содержат неверное значение. Какое значение окажется в памяти, нельзя предсказать. Такое положение дел нельзя допустить, поэтому используются системы согласования кэшей.
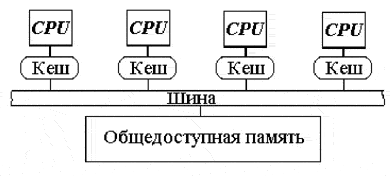
Современные системы SMP архитектуры состоят, как правило, из нескольких однородных серийно выпускаемых микропроцессоров и массива общей памяти, подключение к которой производится либо с помощью общей шины, либо с помощью коммутатора.
Наличие общей памяти значительно упрощает организацию взаимодействия процессоров между собой и упрощает программирование, поскольку параллельная программа работает в едином адресном пространстве. Однако за этой кажущейся простотой скрываются большие проблемы, присущие системам этого типа. Все они, так или иначе, связаны с оперативной памятью. Дело в том, что в настоящее время даже в однопроцессорных системах самым узким местом является оперативная память, скорость работы которой значительно отстала от скорости работы процессора. Для того чтобы сгладить этот разрыв, современные процессоры снабжаются скоростной буферной памятью (кэш-памятью), скорость работы которой значительно выше, чем скорость работы основной памяти. В качестве примера приведем данные измерения пропускной способности кэш-памяти и основной памяти для персонального компьютера на базе процессора Pentium III 1000 Мгц.
В данном процессоре кэш-память имеет два уровня:
Очевидно, что при проектировании многопроцессорных систем эти проблемы еще более обостряются, так как память должна быть достаточно быстродействующей, чтобы обеспечивать данными сразу несколько процессоров. Помимо хорошо известной проблемы конфликтов при обращении к общей шине памяти возникла и новая проблема, связанная с иерархической структурой организации памяти современных компьютеров.
В мультипроцессорных системах, использующих микропроцессоры с кэш-памятью, подсоединенные к централизованной общей памяти, протоколы наблюдения приобрели популярность, поскольку для опроса состояния кэшей они могут использовать заранее существующее физическое соединение - шину памяти.
Неформально, проблема когерентности памяти состоит в необходимости гарантировать, что любое считывание элемента данных возвращает последнее по времени записанное в него значение. Это определение не совсем корректно, поскольку невозможно требовать, чтобы операция считывания мгновенно видела значение, записанное в этот элемент данных некоторым другим процессором. Если, например, операция записи на одном процессоре предшествует операции чтения той же ячейки на другом процессоре в пределах очень короткого интервала времени, то невозможно гарантировать, что чтение вернет записанное значение данных, поскольку в этот момент времени записываемые данные могут даже не покинуть процессор. Вопрос о том, когда точно записываемое значение должно быть доступно процессору, выполняющему чтение, определяется выбранной моделью согласованного (непротиворечивого) состояния памяти и связан с реализацией синхронизации параллельных вычислений. Поэтому с целью упрощения предположим, что мы требуем только, чтобы записанное операцией записи значение было доступно операции чтения, возникшей немного позже записи и что операции записи данного процессора всегда видны в порядке их выполнения.
С этим простым определением согласованного состояния памяти мы можем гарантировать когерентность путем обеспечения двух свойств:
Первое свойство очевидно связано с определением когерентного (согласованного) состояния памяти: если бы процессор всегда бы считывал только старое значение данных, то память была бы некогерентна.
Необходимость строго последовательного выполнения операций записи является более тонким, но также очень важным свойством. Представим себе, что строго последовательное выполнение операций записи не соблюдается. Тогда процессор P1 может записать данные в ячейку, а затем в эту ячейку выполнит запись процессор P2. Строго последовательное выполнение операций записи гарантирует два важных следствия для этой последовательности операций записи. Во-первых, оно гарантирует, что каждый процессор в машине в некоторый момент времени будет наблюдать запись, выполняемую процессором P2. Если последовательность операций записи не соблюдается, то может возникнуть ситуация, когда какой-нибудь процессор будет наблюдать сначала операцию записи процессора P2, а затем операцию записи процессора P1, и будет хранить это записанное P1 значение неограниченно долго. Более тонкая проблема возникает с поддержанием разумной модели порядка выполнения программ и когерентности памяти для пользователя: представьте, что третий процессор постоянно читает ту же самую ячейку памяти, в которую записывают процессоры P1 и P2; он должен наблюдать сначала значение, записанное P1, а затем значение, записанное P2. Возможно он никогда не сможет увидеть значения, записанного P1, поскольку запись от P2 возникла раньше чтения. Если он даже видит значение, записанное P1, он должен видеть значение, записанное P2, при последующем чтении. Подобным образом любой другой процессор, который может наблюдать за значениями, записываемыми как P1, так и P2, должен наблюдать идентичное поведение. Простейший способ добиться таких свойств заключается в строгом соблюдении порядка операций записи, чтобы все записи в одну и ту же ячейку могли наблюдаться в том же самом порядке. Это свойство называется последовательным выполнением (сериализацией) операций записи (write serialization). Вопрос о том, когда процессор должен увидеть значение, записанное другим процессором достаточно сложен и имеет заметное воздействие на производительность, особенно в больших машинах.
Имеются две методики поддержания описанной выше когерентности. Один из методов заключается в том, чтобы гарантировать, что процессор должен получить исключительные права доступа к элементу данных перед выполнением записи в этот элемент данных. Этот тип протоколов называется протоколом записи с аннулированием (write ivalidate protocol), поскольку при выполнении записи он аннулирует другие копии. Это наиболее часто используемый протокол как в схемах на основе справочников, так и в схемах наблюдения. Исключительное право доступа гарантирует, что во время выполнения записи не существует никаких других копий элемента данных, в которые можно писать или из которых можно читать: все другие кэшированные копии элемента данных аннулированы. Чтобы увидеть, как такой протокол обеспечивает когерентность, рассмотрим операцию записи, вслед за которой следует операция чтения другим процессором. Поскольку запись требует исключительного права доступа, любая копия, поддерживаемая читающим процессором должна быть аннулирована (в соответствии с названием протокола). Таким образом, когда возникает операция чтения, произойдет промах кэш-памяти, который вынуждает выполнить выборку новой копии данных. Для выполнения операции записи мы можем потребовать, чтобы процессор имел достоверную (valid) копию данных в своей кэш-памяти прежде, чем выполнять в нее запись. Таким образом, если оба процессора попытаются записать в один и тот же элемент данных одновременно, один из них выиграет состязание у второго (мы вскоре увидим, как принять решение, кто из них выиграет) и вызывает аннулирование его копии. Другой процессор для завершения своей операции записи должен сначала получить новую копию данных, которая теперь уже должна содержать обновленное значение.
Альтернативой протоколу записи с аннулированием является обновление всех копий элемента данных в случае записи в этот элемент данных. Этот тип протокола называется протоколом записи с обновлением (write update protocol) или протоколом записи с трансляцией (write broadcast protocol). Обычно в этом протоколе для снижения требований к полосе пропускания полезно отслеживать, является ли слово в кэш-памяти разделяемым объектом, или нет, а именно, содержится ли оно в других кэшах. Если нет, то нет никакой необходимости обновлять другой кэш или транслировать в него обновленные данные.
Разница в производительности между протоколами записи с обновлением и с аннулированием определяется тремя характеристиками:
Эти две схемы во многом похожи на схемы работы кэш-памяти со сквозной записью и с записью с обратным копированием. Также как и схема задержанной записи с обратным копированием требует меньшей полосы пропускания памяти, так как она использует преимущества операций над целым блоком, протокол записи с аннулированием обычно требует менее тяжелого трафика, чем протокол записи с обновлением, поскольку несколько записей в один и тот же блок кэш-памяти не требуют трансляции каждой записи. При сквозной записи память обновляется почти мгновенно после записи (возможно с некоторой задержкой в буфере записи). Подобным образом при использовании протокола записи с обновлением другие копии обновляются так быстро, насколько это возможно. Наиболее важное отличие в производительности протоколов записи с аннулированием и с обновлением связано с характеристиками прикладных программ и с выбором размера блока.
В дополнение к аннулированию или обновлению соответствующих копий блока кэш-памяти, в который производилась запись, мы должны также разместить элемент данных, если при записи происходит промах кэш-памяти. В кэш-памяти со сквозной записью последнее значение элемента данных найти легко, поскольку все записываемые данные всегда посылаются также и в память, из которой последнее записанное значение элемента данных может быть выбрано (наличие буферов записи может привести к некоторому усложнению).
Однако для кэш-памяти с обратным копированием задача нахождения последнего значения элемента данных сложнее, поскольку это значение скорее всего находится в кэше, а не в памяти. В этом случае используется та же самая схема наблюдения, что и при записи: каждый процессор наблюдает и контролирует адреса, помещаемые на шину. Если процессор обнаруживает, что он имеет модифицированную („грязную“) копию блока кэш-памяти, то именно он должен обеспечить пересылку этого блока в ответ на запрос чтения и вызвать отмену обращения к основной памяти. Поскольку кэши с обратным копированием предъявляют меньшие требования к полосе пропускания памяти, они намного предпочтительнее в мультипроцессорах, несмотря на некоторое увеличение сложности. Поэтому далее мы рассмотрим вопросы реализации кэш-памяти с обратным копированием.
Для реализации процесса наблюдения могут быть использованы обычные теги кэша. Более того, упоминавшийся ранее бит достоверности (valid bit), позволяет легко реализовать аннулирование. Промахи операций чтения, вызванные либо аннулированием, либо каким-нибудь другим событием, также не сложны для понимания, поскольку они просто основаны на возможности наблюдения. Для операций записи мы хотели бы также знать, имеются ли другие кэшированные копии блока, поскольку в случае отсутствия таких копий, запись можно не посылать на шину, что сокращает время на выполнение записи, а также требуемую полосу пропускания.
Чтобы отследить, является ли блок разделяемым, мы можем ввести дополнительный бит состояния (shared), связанный с каждым блоком, точно также как это делалось для битов достоверности (valid) и модификации (modified или dirty) блока. Добавив бит состояния, определяющий является ли блок разделяемым, мы можем решить вопрос о том, должна ли запись генерировать операцию аннулирования в протоколе с аннулированием, или операцию трансляции при использовании протокола с обновлением. Если происходит запись в блок, находящийся в состоянии „разделяемый“ при использовании протокола записи с аннулированием, кэш формирует на шине операцию аннулирования и помечает блок как частный (private). Никаких последующих операций аннулирования этого блока данный процессор посылать больше не будет. Процессор с исключительной (exclusive) копией блока кэш-памяти обычно называется „владельцем“ (owner) блока кэш-памяти.
При использовании протокола записи с обновлением, если блок находится в состоянии „разделяемый“, то каждая запись в этот блок должна транслироваться. В случае протокола с аннулированием, когда посылается операция аннулирования, состояние блока меняется с „разделяемый“ на „неразделяемый“ (или „частный“). Позже, если другой процессор запросит этот блок, состояние снова должно измениться на „разделяемый“. Поскольку наш наблюдающий кэш видит также все промахи, он знает, когда этот блок кэша запрашивается другим процессором, и его состояние должно стать „разделяемый“.
Поскольку любая транзакция на шине контролирует адресные теги кэша, потенциально это может приводить к конфликтам с обращениями к кэшу со стороны процессора. Число таких потенциальных конфликтов можно снизить применением одного из двух методов: дублированием тегов, или использованием многоуровневых кэшей с „охватом“ (inclusion), в которых уровни, находящиеся ближе к процессору являются поднабором уровней, находящихся дальше от него. Если теги дублируются, то обращения процессора и наблюдение за шиной могут выполняться параллельно. Конечно, если при обращении процессора происходит промах, он должен будет выполнять арбитраж с механизмом наблюдения для обновления обоих наборов тегов. Точно также, если механизм наблюдения за шиной находит совпадающий тег, ему будет нужно проводить арбитраж и обращаться к обоим наборам тегов кэша (для выполнения аннулирования или обновления бита „разделяемый“), возможно также и к массиву данных в кэше, для нахождения копии блока. Таким образом, при использовании схемы дублирования тегов процессор должен приостановиться только в том случае, если он выполняет обращение к кэшу в тот же самый момент времени, когда механизм наблюдения обнаружил копию в кэше. Более того, активность механизма наблюдения задерживается только когда кэш имеет дело с промахом.
Чтобы обойти проблемы когерентности, разделяемые (общие) данные не кэшируются. Конечно, с помощью программного обеспечения можно реализовать некоторую схему кэширования разделяемых данных путем их копирования из общего адресного пространства в локальную память конкретного узла. В этом случае когерентностью памяти также будет управлять программное обеспечение. Преимуществом такого подхода является практически минимальная необходимая поддержка со стороны аппаратуры, хотя наличие, например, таких возможностей как блочное (групповое) копирование данных было бы весьма полезным. Недостатком такой организации является то, что механизмы программной поддержки когерентности подобного рода кэш-памяти компилятором весьма ограничены. Существующая в настоящее время методика в основном подходит для программ с хорошо структурированным параллелизмом на уровне программного цикла.
Машины с архитектурой, подобной Cray T3D, называют процессорами (машинами) с массовым параллелизмом (MPP Massively Parallel Processor). К машинам с массовым параллелизмом предъявляются взаимно исключающие требования. Чем больше объем устройства, тем большее число процессоров можно расположить в нем, тем длиннее каналы передачи управления и данных, а значит и меньше тактовая частота. Происшедшее возрастание нормы массивности для больших машин до 512 и даже 64К процессоров обусловлено не ростом размеров машины, а повышением степени интеграции схем, позволившей за последние годы резко повысить плотность размещения элементов в устройствах. Топология сети обмена между процессорами в такого рода системах может быть различной. В таблице приведены характеристики сети обмена для некоторых коммерческих MPP.
| Фирма | Название | Кол-во | Базовая | Связь | Полоса | Год |
| узлов | топология | (бит) | (Мбайт/с) | |||
| Thinking | CM-2 | 1024-4096 | 12-мерный куб | 1 | 1 | 1987 |
| Machines | ||||||
| nCube | nCube/ten | 1-1024 | 10-мерный куб | 1 | 1.2 | 1987 |
| Intel | iPSC/2 | 16-128 | 7-мерный куб | 1 | 2 | 1988 |
| Maspar | MP-1216 | 32-512 | 2-мерная сеть+ | 1 | 3 | 1989 |
| ступенчатая Omega | ||||||
| Intel | Delta | 540 | 2-мерная сеть | 16 | 40 | 1991 |
| Thinking | CM-5 | 32-2048 | fat-дерево | 4 | 20 | 1991 |
| Machines | ||||||
| Meiko | CS-2 | 2-1024 | fat-дерево | 8 | 50 | 1992 |
| Intel | Paragon | 4-1024 | 2-мерная сеть | 16 | 200 | 1992 |
| Cray | T3D | 16-1024 | 3-мерный тор | 16 | 300 | 1993 |
| Research |
Для построения крупномасштабных систем альтернативой рассмотренному в предыдущем разделе протоколу наблюдения может служить протокол на основе справочника, который отслеживает состояние кэшей. Такой подход предполагает, что логически единый справочник хранит состояние каждого блока памяти, который может кэшироваться. В справочнике обычно содержится информация о том, в каких кэшах имеются копии данного блока, модифицировался ли данный блок и т.д. В существующих реализациях этого направления справочник размещается рядом с памятью. Имеются также протоколы, в которых часть информации размещается в кэш-памяти. Положительной стороной хранения всей информации в едином справочнике является простота протокола, связанная с тем, что вся необходимая информация сосредоточена в одном месте. Недостатком такого рода справочников является его размер, который пропорционален общему объему памяти, а не размеру кэш-памяти. Это не составляет проблемы для машин, состоящих, например, из нескольких сотен процессоров, поскольку связанные с реализацией такого справочника накладные расходы можно преодолеть. Но для машин большего размера необходима методика, позволяющая эффективно масштабировать структуру справочника.
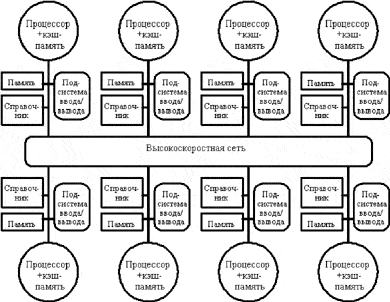
В частности, чтобы предотвратить появление узкого горла в системе, связанного с единым справочником, можно распределить части этого справочника вместе с устройствами распределенной локальной памяти. Таким образом можно добиться того, что обращения к разным справочникам (частям единого справочника) могут выполняться параллельно, точно также как обращения к локальной памяти в распределенной памяти могут выполняться параллельно, существенно увеличивая общую полосу пропускания памяти. В распределенном справочнике сохраняется главное свойство подобных схем, заключающееся в том, что состояние любого разделяемого блока данных всегда находится во вполне определенном известном месте. На рис. показан общий вид подобного рода машины с распределенной памятью.
|
Каждый модуль довольно часто является SMP-системой, которая дополнена специальной системой доступа к удаленно памяти.
Впервые идею гибридной архитектуры предложил Стив Воллох и воплотил в системах серии Exemplar. Вариант Воллоха - система, состоящая из 8-ми SMP узлов. Фирма HP купила идею и реализовала на суперкомпьютерах серии SPP. Идею подхватил Сеймур Крей (Seymour R.Cray) и добавил новый элемент - когерентный кэш, создав так называемую архитектуру cc-NUMA (Cache Coherent Non-Uniform Memory Access), которая расшифровывается как "неоднородный доступ к памяти с обеспечением когерентности кэшей". Он ее реализовал на системах типа Origin.
Аппаратура усложняется за счет появления единой коммуникационной среды, к качеству которой предъявляются высокие требования. Програмное обеспечение усложняется в основном за счет необходимости создания новой ОС, учитывающей особенности архитектуры.
Как правило, несколько таких процессоров (1-16) работают одновременно над общей памятью (аналогично SMP) в рамках многопроцессорных конфигураций. Несколько таких узлов могут быть объединены с помощью коммутатора (аналогично MPP).
Параллелизм обработки обеспечивается за счет представления данных в виде векторов значений. Одна и та же операция производится над каждым элементом вектора, что обеспечивает SIMD-обработку данных. Некоторые авторы утверждают, что такие машины не являются параллельными, так как векторы обрабатываются последовательно (параллельность имеется только на уровне компонентов вектора) и относят их к SISD-классу машин.
Кластеры относятся к MPP-системам, от остальных архитектур они отличаются следующими параметрами:
Кластеризация может быть осуществлена на разных уровнях компьютерной системы, включая аппаратное обеспечение, операционные системы, программы-утилиты, системы управления и приложения. Чем больше уровней системы объединены кластерной технологией, тем выше надежность, масштабируемость и управляемость кластера.
Кластерные суперкомпьютерные системы являются самыми дешевыми, поскольку собираются на базе стандартных комплектующих элементов („off the shelf“), процессоров, коммутаторов, дисков и внешних устройств.
Условное деление на классы предложено Язеком Радаевским и Дугласом Эдлайном:
Отметим, что границы между этими типами кластеров до некоторой степени размыты, и часто существующий кластер может иметь такие свойства или функции, которые выходят за рамки перечисленных типов. Более того, при конфигурировании большого кластера, используемого как система общего назначения, приходится выделять блоки, выполняющие все перечисленные функции.
Преимущество кластеризации для повышения работоспособности становится очевидным в случае сбоя какого-либо узла: при этом другой узел кластера может взять на себя нагрузку неисправного узла, и пользователи не заметят прерывания в доступе. Возможности масштабируемости кластеров позволяют многократно увеличивать производительность приложений для большего числа пользователей.
Кластеры для высокопроизводительных вычислений предназначены для параллельных расчётов. Эти кластеры обычно собраны из большого числа компьютеров. Разработка таких кластеров является сложным процессом, требующим на каждом шаге аккуратных согласований таких вопросов как инсталляция, эксплуатация и одновременное управление большим числом компьютеров, технические требования параллельного и высокопроизводительного доступа к одному и тому же системному файлу (или файлам) и межпроцессорная связь между узлами и координация работы в параллельном режиме. Эти проблемы проще всего решаются при обеспечении единого образа операционной системы для всего кластера.
Многопоточные системы используются для обеспечения единого интерфейса к ряду ресурсов, которые могут со временем произвольно наращиваться (или сокращаться) в размере. Наиболее общий пример этого представляет собой группа Веб-серверов.
В 1994 году Томас Стерлинг (Sterling) и Дон Беккер (Becker) создали 16-и узловой кластер из процессоров Intel DX4, соединенных сетью 10Мбит/с Ethernet с дублированием каналов. Они назвали его „Beowulf“ по имени героя древнескандинавского эпоса. Кластер возник в центре NASA Goddard Space Flight Center для поддержки необходимыми вычислительными ресурсами проекта Earth and Space Sciences. Проектно-конструкторские работы над кластером быстро превратились в то, что известно сейчас под названием проект Beowulf. Проект стал основой общего подхода к построению параллельных кластерных компьютеров и описывает многопроцессорную архитектуру, которая может с успехом использоваться для параллельных вычислений. Beowulf-кластер, как правило, является системой, состоящей из одного серверного узла (который обычно называется головным узлом), а также одного или нескольких подчинённых узлов (вычислительных узлов), соединённых посредством стандартной компьютерной сети. Система строится с использованием стандартных аппаратных компонент, таких как ПК, запускаемых под Linux, стандартных сетевых адаптеров (например, Ethernet) и коммутаторов. Нет особого программного пакета „Beowulf“. Вместо этого имеется несколько кусков программного обеспечения, которые многие пользователи нашли пригодными для построения кластеров Beowulf. Beowulf использует такие программные продукты как операционную систему Linux, системы передачи сообщений PVM, MPI, системы управления очередями заданий и другие стандартные продукты. Серверный узел контролирует весь кластер и обслуживает файлы, направляемые к клиентским узлам.
Термин „мета-компьютинг“ возник вместе с развитием высокоскоростной сетевой инфраструктуры в начале 90-х годов и относился к объединению нескольких разнородных вычислительных ресурсов в локальной сети организации для решения одной задачи. Основная цель построения мета-компьютера в то время заключалась в оптимальном распределении частей работы по вычислительным системам различной архитектуры и различной мощности. Например, предварительная обработка данных и генерация сеток для счета могли производится на пользовательской рабочей станции, основное моделирование на векторно-конвейерном суперкомпьютере, решение больших систем линейных уравнений - на массивно-паралллельной системе, а визуализация результатов - на специальной графической станции.
В дальнейшем, исследования в области технологий мета-компьютинга были развиты в сторону однородного доступа к вычислительным ресурсам большого числа (вплоть до нескольких тысяч) компьютеров в локальной или глобальной сети. Компонентами „мета-компьютера“ могут быть как простейшие ПК, так и мощные массивно-параллельные системы. Что важно, мета-компьютер может не иметь постоянной конфигурации - отдельные компоненты могут включаться в его конфигурацию или отключаться от нее; при этом технологии мета-компьютинга обеспечивают непрерывное функционирование системы в целом. Современные исследовательские проекты в этой области направлены на обеспечение прозрачного доступа пользователей через Интернет к необходимым распределенным вычислительным ресурсам, а также прозрачного подключения простаивающих вычислительных систем к мета-компьютерам.
Очевидно, что наилучшим образом для решения на мета-компьютерах подходят задачи переборного и поискового типа, где вычислительные узлы практически не взамодействуют друг с другом и основную часть работы производят в автономном режиме. Основная схема работы в этом случае примерно такая: специальный агент, расположенный на вычислительном узле (компьютере пользователя), определяет факт простоя этого компьютера, соединяется с управляющим узлом мета-компьютера и получает от него очередную порцию работы (область в пространстве перебора). По окончании счета по данной порции вычислительный узел передает обратно отчет о фактически проделанном переборе или сигнал о достижении цели поиска.
Сейчас в мире работают множество мета-компьютеро, в том числе и вкоммерческих. Они обсчитывают хорошо распараллеливаемые задачи: высокоточное вычисление числа pi, взлом шифров RSA, поиск простых чисел Мерсена (вида 2p-1), обработка данных, поступающих с радиотелескопов и т.д.
|
Иерархическая шина ялвяется двумерной структурой, в которой множество локальных шин объединены глобальной шиной (или несколькими шинами). Эта схема лучше одномерной шины, если удается сделать большую часть пересылок локальными. Если же этого добиться невозможно и имеются множественные пересылки между локальными сегментами, то такая организация оказывается даже хуже одномерной шины.
|
Тем не менее, подобная организация иногда применяется. Например, так могут быть связаны обрабатывающие элементы векторного процессора, хотя обычно при этом и узлы, и связи получаются неоднородными.
|
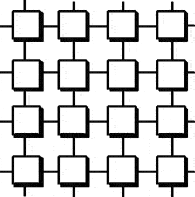
Иногда решетка образуется двумя наборами шин - горизонтальным и вертикальным. В этом случае каждый процессор имеет два порта. Необходимо обеспечивать схемы маршрутизации для сообщений, которые идут в другие столбец и/или строку.
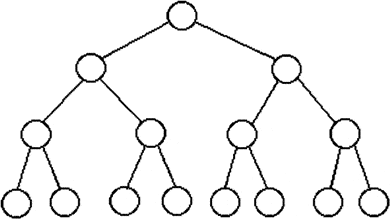
Однако простое дерево имеет узкое место. Им являются два узла - потомки корня. Сам корень должен только пересылать пакеты из левого поддерева в правое, а эти два узла должны осуществлять маршрутизацию для сообщений всего своего поддерева, анализируя адреса получателей данных.
|
Чтобы избавиться от этой проблемы прибегают к схеме X-дерева (рис. , рис. ). В этом дереве вычислительные узлы находятся в листьях дерева, и организованные дополнительные связи, позволяющие листьям организовывать передачу данных внутри подддерева, не затрагивая более высокие уровни дерева.
|
|
Другой подход к решению той же проблемы прдоставляет „толстое дерево“ (рис. ). Это прямой способ решения, при котором связи поддеревьев более высокого уровня обладают более высокой производительностью.
|
|
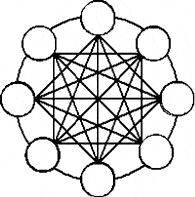
Гиперкубовая архитектура является одной из наиболее эффективных топологий соединения вычислительных узлов. Она имеет малый диаметр, например, для 64 узлов диаметр равен 6. Для сравнения заметим, что в системе с двумерной решетко эта величина составит 14 шагов. Это является следствием того, при увеличении количества узлов в два раза максимальное расстояние между ними увеличивается всего на 1.
Очевидно, что для образования такой архитектуры на вычислительных узлах необходимо иметь достаточное количество коммуникационных каналов. Например, в процессорных модулях nCUBE2 имеется 13 таких каналов, что позволяет собирать системы, состоящие из 8192 процессоров.
Для многих топологий сетей их эффективность напрямую зависит от приложения, от характеристик обмена между процессорами. Это наталкивает на мысль перестройки топологии коммуникационной сети для нужд запущенного в данный момент приложения.
|
В принципе одна архитектура может эмулировать другую, то есть если, например, реализовать полносвязную сеть, то на ее базе можно осуществить кольцевое соединение узлов (равно как и любое другое). Но такой выход неприемлем для систем со сколь-нибудь значимым количеством узлов (например, 10).
Если стоит задача создать такую сеть, то можно использовать концепцию черного ящика. Сеть в этом случае представляет собой некоторую среду, к которой подключены вычислительные узлы (рис. 23). Эта среда реализована в виде программироемого коммутатора, который еще называется кроссбаром (crossbar) в соответствии с терминологией связистов.
Обычно при разработке межпроцессорных коммуникаций используют многоуровневую динамическую сеть, состоящую из небольших коммутаторов(например, 2×2), объединенных в несколько уровней
|
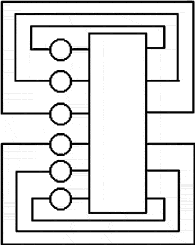
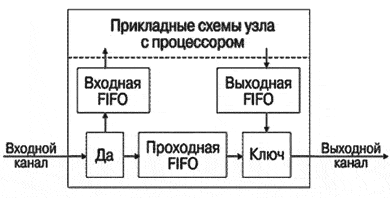
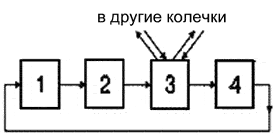
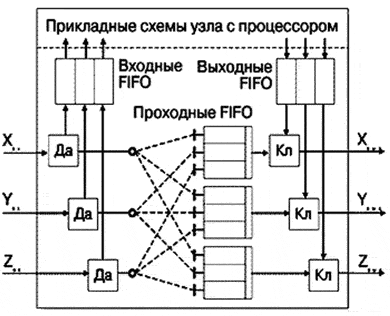
Узел PСИ (рис. 24), получает через входной канал пакеты символов, состоящих из двух байтов. В случае совпадения значения первого символа с присвоенным узлу адресом, пакет через входную очередь FIFO передается в прикладные схемы узла на обработку, например процессором. При несовпадении пакет через проходную FIFO и ключ попадает в выходной канал. Ключ нужен для отстаивания проходящего пакета на время выдачи пакета обработанной информации через выходную FIFO.
|
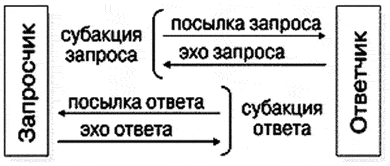
Узлы соединяются в колечки (рис. 25), в которых пакеты продвигаются всегда в одном направлении (на рисунке один из узлов выполнен в качестве переключателя на другие колечки). Переключатели позволяют образовать из колечек сети произвольной конфигурации, например регулярные структуры (рис. ). Транзакции в системе PСИ раздельные и состоят из субакции запроса и субакции ответа (рис. ). Ответ может быть подготовлен и выдан через произвольное время после получения пакета запроса процессором узла-ответчика. Это получение ответчик подтверждает немедленной выдачей эха запроса. Hа пакет ответа запросчик выдает эхо ответа. Таким образом, полная транзакция образуется из четырех пакетов (рис. ).
|
Будем расчитывать следующие характеристики:
Объем эха всегда составляет 8 байтов, включая циклический избыточный код (ЦИК). После любого пакета всегда идет хотя бы один свободный символ. Объем пакетов запроса и ответа зависит от количества байтов данных D, передаваемых в пакете, и от наличия расширенного адреса. При передаче пакетов (рис. ), полный объем транзакции в байтах равен:
|
|
Чтобы найти Tk, сначала определим длительность полной транзакции Tt=Vt/S и задержку T4p четырех пакетов одной транзакции, проходящих через узлы колечка. Дополнительная задержка каждого пакета на один такт 2 нс происходит в двух местах каждого узла: в дешифраторе адреса и в проходной FIFO, поэтому задержка во всей транзакции в одном узле T4pu=4·(2+2)=16 нс. Hужно учитывать, что пакеты запроса и ответа никогда не проходят все узлы колечка, поскольку после их приема промежуточным узлом далее выдается эхо. В среднем пакеты проходят полколечка, поэтому суммарная задержка пакетов в колечке равна T4h=[(T4pu·k)/2]=8k нс.
В идеальном случае, когда пакеты начинают движение сразу же после готовности, не отстаиваясь в выходной FIFO, суммарное время продвижения всех k транзакций, вырабатываемых процессорами, через все k узлов колечка равно:
|
В течение этого времени процессор, получивший входные данные, имеет возможность их обрабатывать, выполняя микрозадачу, и готовить выходной пакет. За время Тk процессор может выполнить операции в количестве Qm=P·Tk. Если объем микрозадачи Qm=Qk, то и процессор, и интерфейс работают с полной нагрузкой со 100% эффективностью, при этом производительность процессора и пропускная способность интерфейса согласованы. Если объем микрозадачи Qm < Qk или процессор настолько быстр Pў > P, что за время Tk может сделать больше операций Qўk=Pў·Tk > Qk, то процессор недогружен и эффективность его Ep=Qm/Qk < 1. При медленных процессорах и больших объемах микрозадач недогружен интерфейс и его эффективность Ei=Qk/Qm < 1.
В реальности готовность пакетов к отправке из узла может возникнуть в любой момент, например во время передачи стороннего пакета через проходную FIFO. В этом случае выводимый пакет отстаивается в выходной FIFO и выдается в выходной канал сразу же после окончания проходящего пакета. Интерфейс PСИ и в этом случае не простаивает, поэтому сделанные выкладки верны. Hезначительное время отстаивания может быть приплюсовано ко времени выполнения микрозадачи.
В инженерных оценках полезны численные значения величин. Pассчитаем Tk и Qk при разных значениях D в предположении, что в колечке k=10 узлов, скорость передачи по стандарту PСИ S=1 байт/нс, производительность процессора P=0.2 FLOP/нс. Тогда
|
|
Следует также оценить задержки в кабелях, соединяющих узлы. Определим такую суммарную длину кабелей, при которой задержка в кабелях равна времени прохождения одной транзакции через все узлы, и назовем эту длину геометрической длиной транзакции Lt. При скорости распространения сигнала в коаксиальных или оптоволоконных кабелях v=0.2 м/с имеем:
|
Pезультаты расчетов представлены в таблице :
| D, байты | 0 | 16 | 64 | 256 |
| Tk, нс | 1680 | 2000 | 2960 | 6800 |
| Qk, flop | 336 | 400 | 592 | 1360 |
| Lt, м | 33.6 | 40 | 59.2 | 136 |
Pасполагая численными значениями Qk, программист имеет возможность так структурировать программы, чтобы эффективности и процессоров, и интерфейса были поближе к единице.
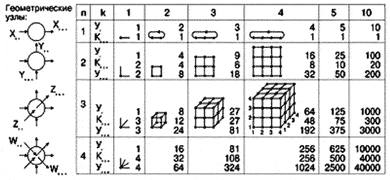
При k і 2 образуются регулярные структуры, удобные для применения на практике, причем для больших систем ценны кубы и гиперкубы. Pассмотрим пути транзакции в кубе, например от узла *(x=2, y=1, z=1) до узла **(4,3,4). Путей множество, но и структурная и геометрическая длина всех путей одинакова, поскольку колечки замкнуты и информация передается в них всегда в одном направлении. Действительно, пакеты запроса от узла * можно пустить через узлы (2,3,1), (3,3,1), (4,3,1), (4,3,2), (4,3,3) до **(4,3,4), а эхо запроса пройдет от этого узла по обратной петле (колечко n=1, k=4) прямо к узлу (4,3,1), далее по обратной петле к (1,3,1), (2,3,1), (2,4,1) и по обратной петле к *(2,1,1). Hа этом пути субакция запроса прошла полные три колечка при структурном пути длиной kc=nk=12 узлов, считая и начальный узел *(2,1,1). В изображенном кубе имеется N=64 геометрических процессорных узлов, следовательно, структурный путь уменьшен более чем в 5 раз в сравнении с путем в одиночном кольце с 64-мя узлами. Отношение [N/kc]=k·[((n-1))/n].
|
В схеме переключателя (рис. 29) штриховыми линиями показаны возможные направления переключения. Проходные FIFO допускают одновременную передачу по любым направлениям. Дешифраторы адресов ДА содержат маршрутные таблицы для определения переключений из одного колечка в другое. Переключатель в геометрическом узле имеет такую же пропускную способность, как и простой узел, но создает в ДА малую дополнительную задержку на один такт 2 нс, необходимую для переключения. Временная эквивалентность узла PСИ и геометрического узла позволяет использовать представленный метод расчета и формулы также и для расчета эффективности процессоров в любых гиперкубах. Для этого нужно лишь определить общее число узлов kcў=nk на структурном пути, а в расчетах вместо k использавать kcў.