|
вернуться в раздел |
Двенадцатого ноября прошла очередная встреча Developers UG-Omsk. Для меня эта встреча была знаменательна тем, что на ней я читал доклад. Ораторское искусство еще есть, куда совершенствовать, но в целом прошло неплохо. :) Выкладываю текст доклада здесь:
Добрый день. Сегодня мне хочется поговорить не о замечательно красивых теоретических аспектах разработки ПО, не о технологиях и языках, а о сугубо практических вещах, с которыми мне приходится сталкиваться постоянно.
Давайте поговорим об ошибках. О процессе программирования говорят часто, разрабатываются технологии программирования, шаблоны проектирования, проводятся разнообразные курсы. Об ошибках говорят редко и, обычно замечают только две вещи: 1) Ошибки есть всегда; 2) Надо стремиться к тому, чтоб ошибок не было.
На мой взгляд, с точки зрения ошибок на разработку смотрят недостаточно часто, хотя на практике заниматься отладкой и исправлением ошибок приходится чаще, чем собственно реализацией новой функциональности.
Ошибки,
обычно недооцениваются. Но недооценка не может длиться долго, рано или
поздно случается что-то такое, что показывает всю важность ошибок.
Обычно это что-то выглядит как-то вот так: 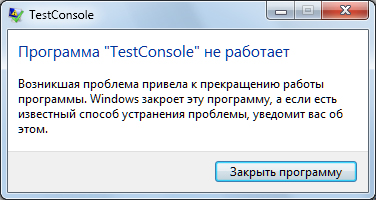
Программист может увидеть такую ошибку с утра в пятницу с припиской от менеджера, что рухнул сданный в эксплуацию программный комплекс, развернутый где-нибудь в США или Китае, и от заказчика пришёл только вот этот скриншот ошибки. И что ошибку надо срочно, в течение часа, максимум дня, исправить.
Если программисту по такой информации не удастся исправить ошибку (а это наверняка), то он может попрощаться с выходными. А если все логирование ошибок находится на таком же уровне, то можно попрощаться и с карьерой.
Программист, хотя бы один раз
побывавший в такой ситуации, начинает во всех своих приложениях писать
перехватчики исключений и выдает уже гораздо более информативные окна.
Например, такие: 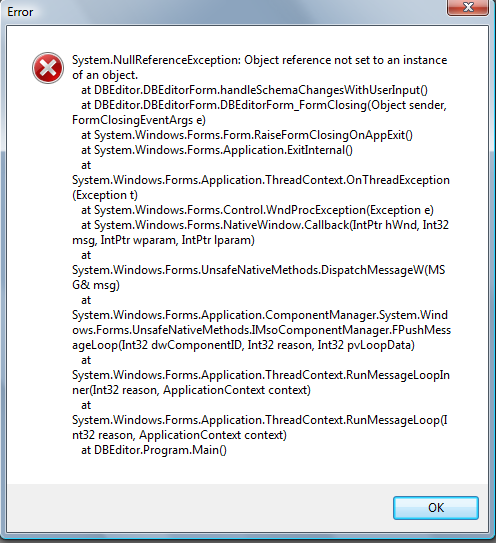
Так же некрасиво, но гораздо информативней. С таким скриншотом уже можно попробоват что-нибудь починить. Кстати, насчет красоты экрана об ошибке также стоит подумать. В моей практике был случай, когда заказчик перестал требовать исправление обрушения программы, после того, как мы сделали нормальный экран ошибки. :) То есть пользователи очень пугались стандартного сообщения о закрытии программы и рапортовали начальству: "Программа поломалась! Все пропало!" Сделали красивое окно с сообщением: "В результате расчета возникла ошибка. Программа будет перезагружена." Пользователи видели, что все идет, как надо и начальство не беспокоили. :)
Особо следует отметить очень опасный подход к сообщениям об ошибках, который встречается не только у новичков, но и, изредка, у опытных разработчиков. Этот подход заключается в том, что вообще никакие сообщения об ошибке не выдаются, а все исключения молча проглатываются. Такое приложение в случае возникновения ошибок выглядит очень странно: перестают работать какие-то кнопки, отключаются пункты меню, появляются пустые окошки без содержимого. И пользователь недоволен, и исправлять это сложно.
Тем не менее, перехват исключений с выводом информативных сообщений -- не панацея. Таким образом можно получить только сиюминутную информацию. То есть мы можем увидеть, что в работающей программе оказалась непроинициализированной какая-то переменная. Почему это случилось, обычно остается загадкой. Поэтому надо активно применять систему логирования. С помощью логирования можно получить описание цепочки событий, которые привели к сбою.
Для логирования есть разные готовые компоненты. Эта тема вообще довольно хорошо проработана, поэтому останавливаться на логировании мы не будем.
Поговорим лучше о юнит-тестировании. Все, что я говорил раньше, касалось ошибок, которые возникали внезапно, в процессе эксплуатации ПО. Юнит-тесты же позволяют автоматически проходить по критическим кускам кода и проверять ошибки.
Успешный прогон unit-тестов выглядит примерно так: 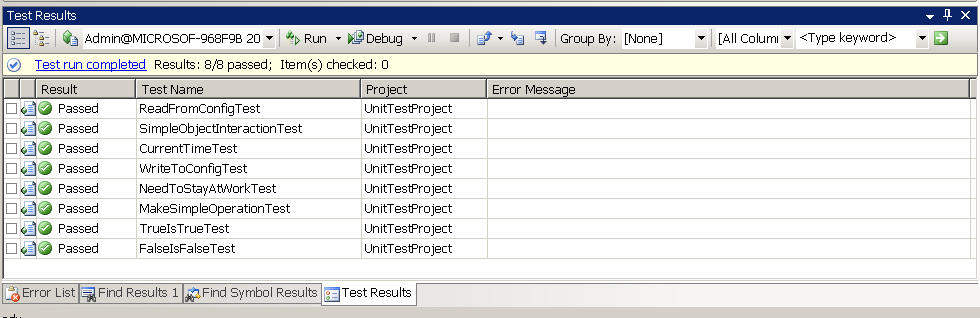
Все
протестировано, все в порядке. Если в результате модификации кода,
нарушается логика работы приложения, то хорошие unit-тесты проведут
регрессионное тестирование и покажут ошибку: 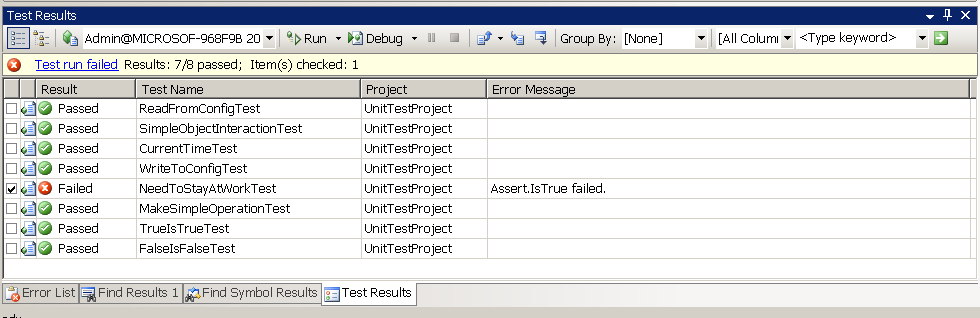
Unit-тест локализует ошибку и сразу показывает, что надо исправлять.
Ну... В идеальном случае. К сожалению, на практике ошибка unit-тестов
выглядит обычно примерно так: 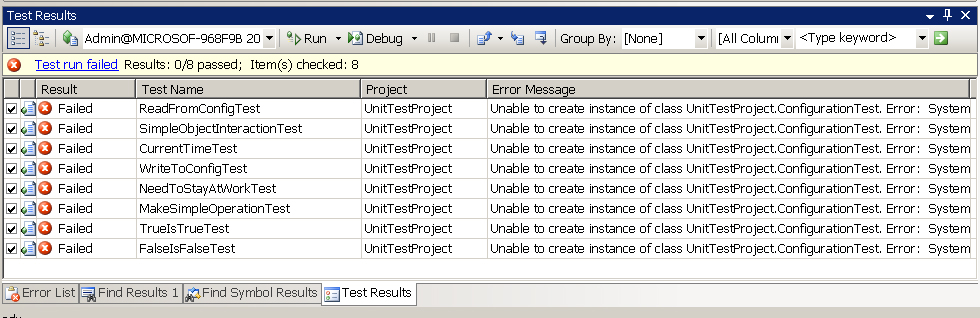
То есть некоторые ошибки ломают все unit-тесты или большую их часть. О
чем это свидетельствует? Это свидетельствует о слишком тесно связанных
блоках, неаккуратном дизайне. Например, в одном из моих проектов было
отдельное вычислительное ядро, которое несло на себе расчетную часть
бизнес-логики. Часто любая ошибка в этом ядре ломала все unit-тесты
ядра. А был еще отдельный модуль конфигурации, любая ошибка в котором
ломала вообще все unit-тесты.
Сами по себе unit-тесты, конечно, никого особо не волнуют, но сильная связанность разных частей системы влечет за собой увеличение стоимости поддержки. На практике был случай. Два разработчика занимались разными частями программы. Один из них исправил какой-то не особо сложный дефект. После следующей сборки вылез новый дефект у другого разработчика. Тот исправил его -- и снова вылез баг у первого разработчика. В результате эта пара дефектов была исправлена 4 раза, до тех пор пока не пришел тестировщик, не собрал этих разработчиков и не показал им, что это связанные дефекты. Сами разработчики эту связь отследить не могли, так как система сложная, а в коде эти дефекты каждый раз выглядели слегка по-разному. В результате вместо быстрого исправления одиночной ошибки получилась долгая эпопея, вовлекающая сразу несколько человек.
Отдельным случаем идет невозможность написания unit-тестов. Такое бывает, например, когда бизнес-логика тесно переплена с логикой отображения. Или когда бизнес-логика равномерно размазана между визуальными формами, базой данных и различными классами.
То есть, когда вы имеете проблемы с unit-тестами, то скорее всего у вас более глубокие проблемы с ошибками, которые, возможно, потребуют какой-то переделки кода. Кстати, если у вас нет unit-тестов, это не значит, что и проблем нет. Проблемы есть, только о них неизвестно.
Для устранения излишней связности системы производят разбиение по модулям, Layering, Dependepcy Injection и прочее.
Простота
отладки и исправления ошибок должна быть на одном из первых мест в
проектировании приложения. Расскажу еще одну историю: о программе,
отладка которой становилась невозможна, если в отладчике мышкой
перекрестить код.
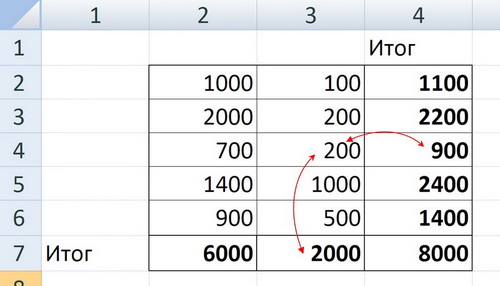
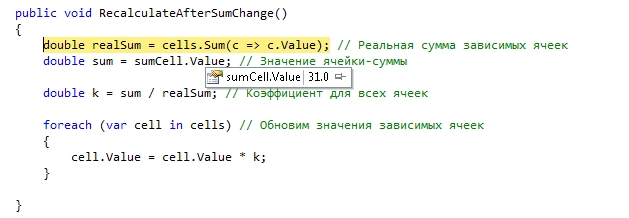
Основная часть программы представляла собой грид с числовыми значениями. В гриде были итоговые ячейки для строк, столбцов, просто групп значений, были неявные связи через различные коэффициенты. В общем в результате любая ячейка зависила от любой другой ячейки. Причем связи эти были очень сложные. В результате любое изменение в любой ячейке затрагивало абсолютно все другие ячейки.
Чтоб значения ячеек всегда были в актуальном состоянии, любое обращение к свойству Value объекта-ячейки вызывало пересчет всех связанных ячеек. Очень сложная логика взаимодействия объектов, которая на практике себя показала гораздо хуже, чем в теории.
В частности эту систему оказалось практически невозможно отлаживать. Основная проблема внешне появлялась именно в том, о чем я уже говорил: достаточно было в отладке перекрестить исходный код программы, чтобы результаты отладки были абсолютно другими, чем при обычной работе программы. На скриншоте хорошо видно, почему так происходило. Как только мышка проходит над свойством Value, Visual Studio пытается получить значение свойства. Так как в геттере объекта вызывается принудительный пересчет всех зависимых объектов, то достаточно один раз провести мышкой над свойством, чтобы изменить всю логику расчетов. В окно Watches также нельзя было добавлять экземпляры этих объектов по тем же причинам.
В результате исправление любой ошибки с расчетами выливалось в двух-трехдневную глубокую отладку. Помучившись несколько месяцев, переписали эту часть системы.
На сегодня это все истории про ошибки, которые я хотел рассказать. Без серьезного структурированного подхода мы мельком пробежались по тому, какое влияние оказывают ошибки на интерфейс, на сервисы, реализуемые в ПО, на архитектуру и дизайн, а также на непосредственное низкоуровневое взаимодействие объектов.
В общем-то, никаких глубоких целей этот доклад не преследовал. Просто мне хочется обратить внимание на еще одну грань разработки ПО. И хочется, чтобы прежде, чем все мы до внедрения какой-то технологии, продукта или решения, подумали бы, а удобно ли нам будет в этой новой среде делать ошибки и исправлять их.